This Week I Learned
Learning is a fundamental part of our daily lives as software engineers. I've got so used to it that I often don't even notice when I learn something new. That's why I've created the "This Week I Learned" journal. Check it out below - or better yet, start your own!
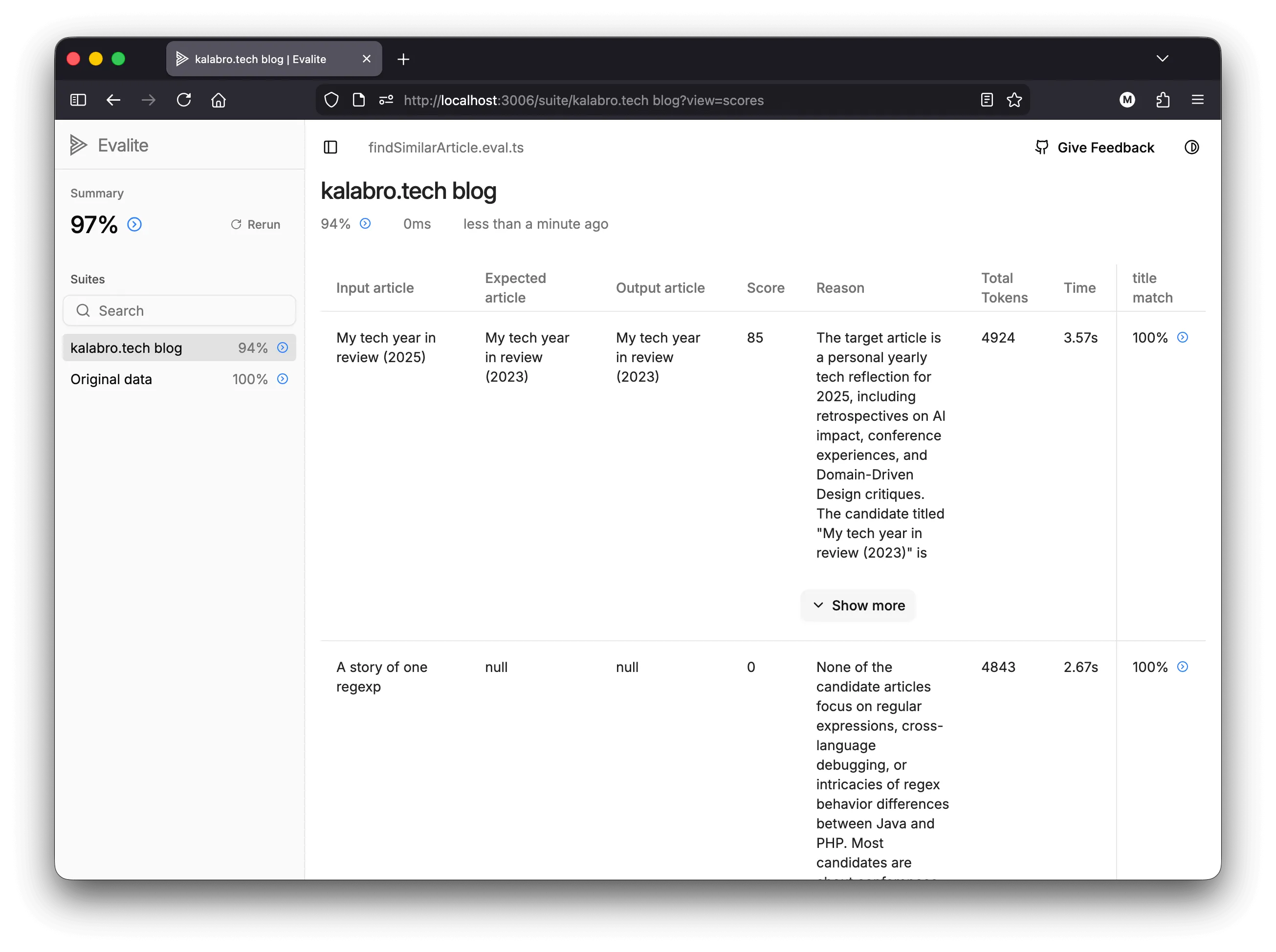
Week of January 5, 2026: Evalite - Vitest for LLMs
Evalite by Matt Pocock is a library for testing AI-powered apps on your local.
Week of December 22, 2025: Chrome DevTools MCP
Access to Chrome Dev Tools capabilities from your coding agent: https://github.com/ChromeDevTools/chrome-devtools-mcp
Week of December 1, 2025: Retry Storm
One great example of this behavior is retries. If you’re only looking at your day-to-day error rate metric, you can be lead to believe that adding more retries makes systems better because it makes the error rate go down. However, the same change can make systems more vulnerable, by converting small outages into sudden (and metastable) periods of internal retry storms.
Week of November 24, 2025: Augmented Coding Patterns by Lada Kesseler
Week of November 10, 2025: Local first note taking app
Paste in your browser address bar:
data:text/html, <html contenteditable>Week of October 27, 2025: Tech on the Toilet
Tech on the Toilet (TotT) is a weekly one-page publication about software development that is posted in bathrooms in Google offices worldwide. At Google, TotT is a trusted source for high quality technical content and software engineering best practices. TotT episodes relevant outside Google are posted to this blog.
Week of October 20, 2025: It’s developer (mis)understanding that’s released in production, not the experts’ knowledge
It’s developer (mis)understanding that’s released in production, not the experts’ knowledge
Week of October 13, 2025: Quality Model - catalog of software quality attributes
Week of August 25, 2025: Amdahl's law
Amdahl’s Law demonstrates the theoretical maximum speedup of an overall system and the concept of diminishing returns. If exactly 50% of the work can be parallelized, the best possible speedup is 2 times. If 95% of the work can be parallelized, the best possible speedup is 20 times. According to the law, even with an infinite number of processors, the speedup is constrained by the unparallelizable portion.
Week of August 18, 2025: eBPF: “This is like putting Javascript into the kernel”
Week of July 28, 2025: JSON Patch
Week of July 21, 2025: Whitespace (programming language)
https://en.wikipedia.org/wiki/Whitespace_(programming_language)
Week of July 14, 2025: OpenAPI Diff
After testing a few tools, https://github.com/oasdiff/oasdiff is just the best!
Week of May 26, 2025: Uncomfortable questions
Another abyss-staring strategy I’ve found useful is to talk to someone else. […]
Of course, it can be hard to find the right person to help you stare into the abyss. The ideal person is someone who is willing to ask you uncomfortable questions—which means you need a close enough relationship for them to feel comfortable doing that, and they need to be wise enough to figure out where the uncomfortable questions are—and they also need to be a good enough listener that talking to them about a tricky topic is fun rather than aversive.
Week of May 19, 2025: IaaS vs PaaS
- IaaS - low level infra APIs (example: AWS)
- PaaS - higher level abstractions that run applications in a scalable sandbox (example: Heroku)
The rise of the orchestration system Kubernetes is in many ways an admission that both PaaS and IaaS have failed to meet enterprise needs. It is an attempt to simplify the IaaS ecosystem by forcing applications to be “cloud-native” and thus need less infrastructure-specific glue. However, for as much as it standardizes, Kubernetes has not been a complexity win. As an intermediary layer trying to support as many different types of compute configurations as possible, it is a classic “leaky” abstraction, requiring far too much detailed configuration to support each application correctly.
Week of April 14, 2025: SharedInformers in Kubernetes
Clients can subscribe to Kubernetes events via SharedInformer (JS example)
As various controllers may be watching over a particular resource and each controller has its informer, which maintains its cache, this could lead to synchronization issues. To solve this problem, it is usually recommended to use sharedInformers as they have a shared cache that multiple controllers can use. In
SharedInformers, only one watch is opened on the Kubernetes API server regardless of the number of consumers, without adding extra overhead.
Week of April 7, 2025: Zero-code OpenTelemetry
OpenTelemetry offers zero-code setup for JS, Java, PHP, Python, Go, and .NET. It’s a huge time-saver, especially for large, established codebases where adding tracing manually is not a trivial task.
Week of March 17, 2025: Playwright MCP
Playwright team has just released their MCP for navigating web in LLMs: https://github.com/microsoft/playwright-mcp Under the hood, it exposes web page accessibility tree that LLMs can easily consume.
Week of March 10, 2025: JSON_DOCUMENT_MAX_DEPTH in MySQL
This week I’ve proudly exceeded MySQL’s JSON_DOCUMENT_MAX_DEPTH limit of 100 (code) 🌀
Week of March 3, 2025: Vitest Browser Mode
Week of February 24, 2025: ulid
Universally Unique Lexicographically Sortable Identifier: https://github.com/ulid/spec
Week of February 17, 2025: Screenplay Pattern
Writing tests at scale requires a more thougtful code organization to keep codebase maintainable. The most popular pattern in testing is Page Object Model, or POM. The Screenplay Pattern is an alternative inspired by Domain-Driven Design and popularized by Serenity/JS.
The Screenplay Pattern in one line: Actors use Abilities to perform Interactions.
For example, an Actor may be given an Ability to browse the Web using a specific browser like Chrome. The Ability would hold a reference to a Chrome WebDriver instance. Then, the Actor could call a Task to load a login page, a second Task to enter username and password, and a final Task to click the “login” button. Each task would access the WebDriver instance through the calling Actor’s Ability to control the Chrome browser.
Week of February 10, 2025: spurious correlations
Week of February 3, 2025: stringsAsFactors
Statisticians use the term “factors” to describe categorical variables, or enums. They are so essential that R coerces all character strings to be factors by default.
Why do we need factor variables to begin with? Because of modeling functions like ‘lm()’ and ‘glm()’. Modeling functions need to treat expand categorical variables into individual dummy variables, so that a categorical variable with 5 levels will be expanded into 4 different columns in your modeling matrix. There’s no way for R to know it should do this unless it has some extra information in the form of the factor class. From this point of view, setting ‘stringsAsFactors = TRUE’ when reading in tabular data makes total sense. If the data is just going to go into a regression model, then R is doing the right thing.
Week of January 27, 2025: ANTLR
https://www.antlr.org/ (plus a ton of community grammars)
Week of January 20, 2025: Common Table Expressions (CTEs)
Complex SQL queries can be broken down into smaller parts using Common Table Expressions (CTEs):
WITH FilteredOrders AS (
SELECT order_id, customer_id, total_amount
FROM orders
WHERE total_amount > 100
),
TopCustomers AS (
SELECT customer_id, COUNT(*) AS order_count
FROM FilteredOrders
GROUP BY customer_id
HAVING COUNT(*) > 3
)
SELECT customer_id, order_count
FROM TopCustomers;Common Table Expressions (CTE) are part of the ANSI standard since SQL:1999. Beware that MySQL always materializes CTEs, which can introduce performance issues.
Week of January 13, 2025: Big Data is Dead
In 2004, when the Google MapReduce paper was written, it would have been very common for a data workload to not fit on a single commodity machine. […] Today, however, a standard instance on AWS uses a physical server with 64 cores and 256 GB of RAM. That’s two orders of magnitude more RAM. […]
One definition of “Big Data” is “whatever doesn’t fit on a single machine. By that definition, the number of workloads that qualify has been decreasing every year.
On a separate note, it’s a lot of fun to debug memory leaks in 256 GB RAM machines.
Week of January 6, 2025: Nemawashi
To ensure you have everyone’s support, it’s helpful to spend time on a consensus-building practice called nemawashi, a process of seeking approval from each significant person on a proposed project before committing to a group decision.